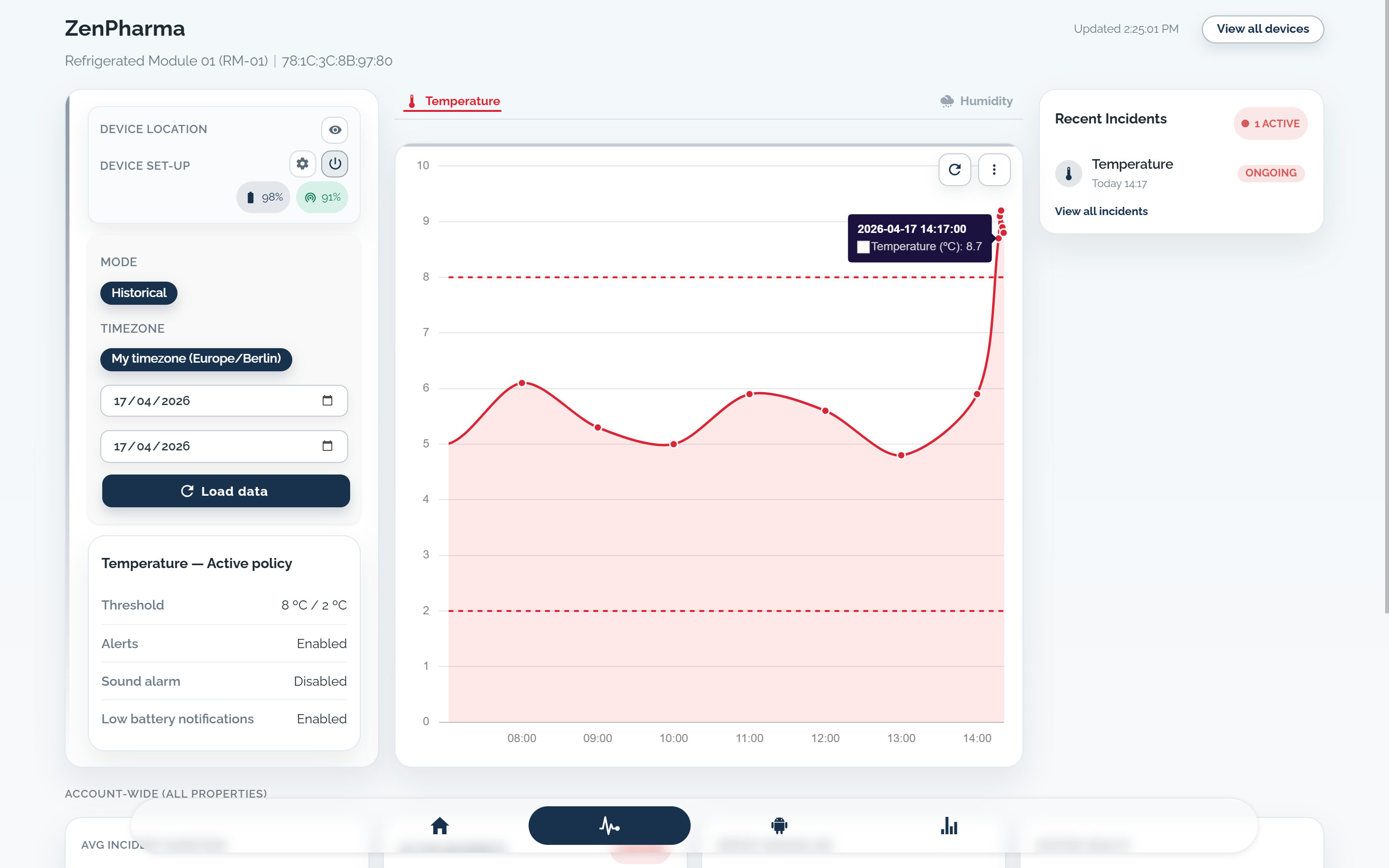
Reading out of range
Incident detected
A fridge, freezer, room, or transport reading moves outside the configured range long enough to count as a real incident.
KRYOS turns an out-of-range reading into a temperature alert or temperature alarm with fast routing, timed escalation, and one traceable record.
The system evaluates the threshold, routes the alert, escalates when needed, and closes with a clean incident record.
A fridge, freezer, room, or transport reading moves outside the configured range long enough to count as a real incident.
Thresholds, delay windows, and severity logic decide whether this becomes a temperature alert or temperature alarm.
The incident is sent through the configured channels and ownership rules for that asset, team, and site.
If the alert is not acknowledged in time, reminders and escalation tiers move it to the next responsible person.
Acknowledgement, notes, timestamps, and follow-up remain attached to the same incident record for review later.
One incident record keeps delivery, escalation, acknowledgement, and follow-up connected.
Alerts need asset-level thresholds, environment-specific alarm profiles, channel routing, escalation ownership, and one record that survives from first alert to final review.
Clear alert response starts with clear boundaries: who sets policy, who works the incident, who escalates across teams, and who reviews the final record.
Urgency, location, and response ownership determine whether an incident should go to SMS, push, WhatsApp, email, or a local sound alarm.
SMS suits urgent out-of-range incidents where the responsible person needs a fridge or freezer alarm on the phone immediately.
Push works when acknowledgement, investigation, or escalation should start directly in the product, not in a standalone message thread.
WhatsApp helps when an incident needs to surface quickly to an on-duty team, especially across shift handoff, transport, or field coordination.
Email fits incident summaries, escalation context, and review-ready details for QA, supervisors, or stakeholders who need more than a short alert.
A sound alarm matters when staff close to the monitored fridge, freezer, room, or storage area need an immediate local warning.
When an alert fires, teams need current value, threshold breach, delivery status, ownership, acknowledgement, and next action in one place.
Request a demo if you need help defining thresholds, escalation, or delivery channels. If your alert setup is already decided, you can go straight to order.